函数的调用
计算机内部的数据存储形式
计算机内部有两种存储形式,分为大端序、小端序。
大端序:
以0123456789abcdef为例,数据最高位01存储在低位,最低位ef存储在高位。
如图:
将此数据按照字符串输出,得到的为:\x01\x23\x45\x67\x89\xab\xcd\xef
小端序:
一0123456789abcdef为例,数据最高位01存储在高位,最低位ef存储在低位。
如图:
将此数据按照字符串输出,得到的为:\xef\xcd\xab\x89\67\x45\x23\x01
两种方式比较
从输出结果来看,大端序符合人类阅读习惯。
从存储逻辑、数学运算规律,小端序更正常。
总结为“大端序:高低低高,小端序:高高低低”
对于linux而言,是以小端序存储,所以我们以字符串的形式输入一个数字时,要注意格式。
比如输入0xdeadbeef这个字符串,输入就是”\xef\xbe\xad\xde”传入程序。
但我们有pwntools,p32即可完成自动转换。
文件描述符
linux系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返
回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来
指向被打开的文件,所有的i/o操作的系统调用都会通过文件描述符。
每个文件描述符会与一个打开的文件相对应,不同的文件描述符也可能指向同一个文件。
相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开。
栈
栈是一种LIFO(先进后出)的数据结构。栈的基本操作有两种:push(压栈)和pop(弹栈)。
由于函数的调用顺序也是LIFO,所以绝大多数系统都是通过栈这一数据结构来维护函数调用关系的。
在Linux系统中,系统为每一个进程都安排了一个栈,进程中每一个调用的函数都有自己独立的栈帧。
栈是由高地址向低地址生长的。高地址为栈底,低地址为栈顶。
很多算法都是用栈实现的。以递归的形式实现一些算法在本质上来说也是利用栈结构。只不过没有在程序
中另外申请一个栈,而是利用函数调用栈。
函数的调用流程
以一下代码为例:
void func_a()
{
//do sth.
return;
}
void func_b()
{
func_a();
int c=1;
return;
}
int main()
{
func_b();
int a=2;
return 0;
}main函数调用func_b,func_b调用func_a。
我们从main函数开始,逐步分析栈帧变化。
当运行到call func_b时main函数的栈帧如下:
rbp指向栈底,rsp指向栈顶,这些栈帧存放了一些main的局部变量。
main函数要调用func_b,main只要call func_b,也就是
push rip;
mov rip func_b;当然被调用的函数还要维护栈帧。(用rsp与rbp开辟空间)
如下
push rbp; /*将调用函数的栈底指针保存*/
mov rbp rsp; /*将栈底指针指向现在的栈顶*/
sub rsp xxx; /*开辟被调用函数的栈帧,此时上一步的rbp就指向栈帧的底*/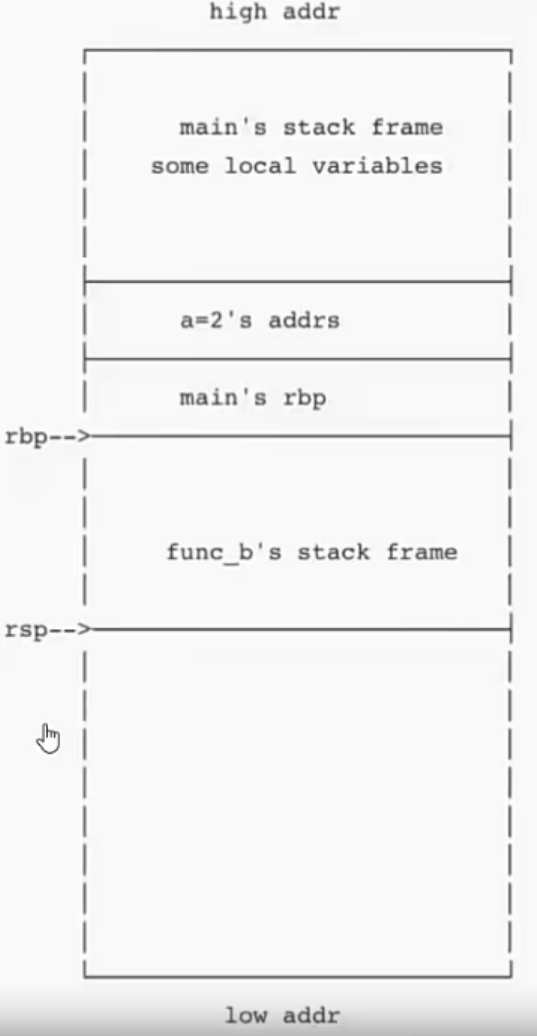
同理根据以上步骤调用func_a也是一样的
如图: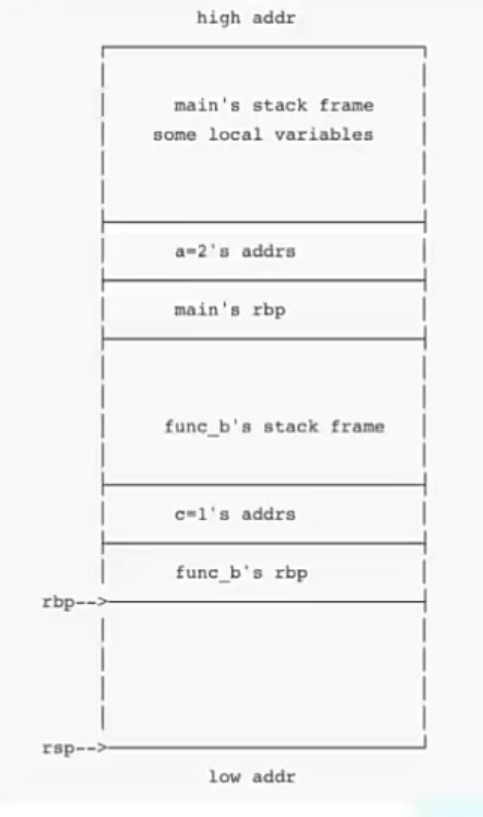
在函数执行结束后返回时,会执行leave;ret;
也就是:
mov rsp rbp;/*将栈顶指针指向栈底*/
pop rbp;/*将栈底指针弹出*/(其实就是改变rsp的值个人认为)
pop rip;/*将fun_b的下一行地址弹出到rip*/栈布局如图:
直到结束函数释放栈空间。
总结如下:
调用函数:将rip压栈,然后将rip赋值为被调用函数的起始地址。这一操作被隐性地内置在call指令中。
被调用函数:先保存调用函数的rbp指针,将自己的rbp指针指向栈顶,然后开辟栈空间自用,此时rbp就成了被调用函数的栈底。
函数返回:恢复栈帧,返回调用函数的返回地址。
调用约定
一般来说,一个函数的返回值会存储到rax寄存器。
x86-64下函数的调用约定为:
从左至右参数依次传递给rdi,rsi,rdx,rcx,r8,r9。
如果一个函数的参数大于六个,则从右至左压入栈中传递。(因为栈LIFO)
syscall指令用于调用系统函数,调用时需要指明系统调用号。系统调用号存在rax寄存器中。之后布置好参数,执行syscall即可。
系统调用的常用调用号码如下:
如调用read(0,buf,size):
mov rax,0 /*read's syscall number.*/
mov rdi,0 /*first arg*/
mov rsi,buf /*second arg.*/
mov rdx,size /*third arg.*/
syscall /*excute read(0,buf,size)*/


